Credit Card Fraud Detection in Python with Code and Implementation
Introduction:
Credit card fraud is a big concern in the finance industry. Detecting and preventing fraud is essential to protect both the financial institutions and their customers. In this article we will go through the process of building a machine-learning model to credit card fraud detection in Python and a publicly available dataset. We will be using Google Colab as the running environment.
Program to Create a Morse Code Translator in Python
Dataset:
We will be using the Credit Card Fraud Detection dataset from Kaggle. This dataset contains 284,807 transactions made by credit cards in September 2013 by European cardholders. The dataset is highly unbalanced, with only 492 fraud transactions out of 284,807 transactions.
Credit Card Fraud Detection in Python Steps:
Import required libraries:
We will be using pandas, numpy, matplotlib, seaborn, sklearn libraries for data analysis, visualization and model building.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
Load the dataset:
We will load dataset into a pandas dataframe using the read_csv() function.
df = pd.read_csv("https://storage.googleapis.com/download.tensorflow.org/data/creditcard.csv")
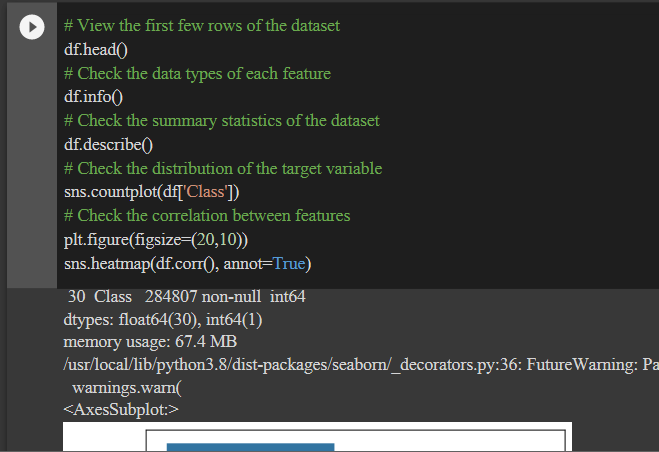
Data Exploration and Visualization:
We will explore dataset to understand its structure, features, and distributions. We will also visualize the dataset to get insights into the data.
# View the first few rows of the dataset
df.head()
# Check the data types of each feature
df.info()
# Check the summary statistics of the dataset
df.describe()
# Check the distribution of the target variable
sns.countplot(df['Class'])
# Check the correlation between features
plt.figure(figsize=(20,10))
sns.heatmap(df.corr(), annot=True)
Data Preprocessing:
We will preprocess dataset by performing data cleaning, scaling, and feature engineering.
# Drop the Time column as it is not useful for the model
df = df.drop('Time', axis=1)
# Scale the Amount column using StandardScaler
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['Amount'] = scaler.fit_transform(df['Amount'].values.reshape(-1,1))
# Split the dataset into training and testing sets
X = df.drop('Class', axis=1)
y = df['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)

Model Building:
We will build logistic regression model to predict the target variable.
# Fit the logistic regression model
lr = LogisticRegression()
lr.fit(X_train, y_train)
# Predict the target variable
y_pred = lr.predict(X_test)

Model Evaluation:
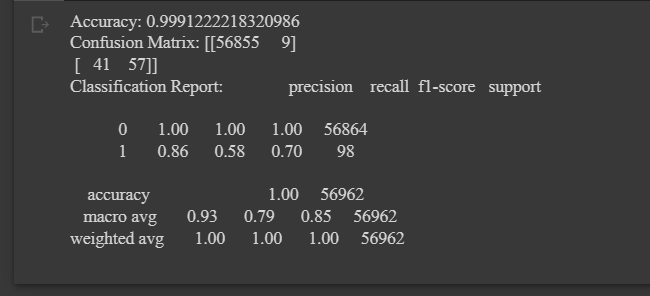
We will evaluate performance of the model using accuracy, confusion matrix, and classification report.
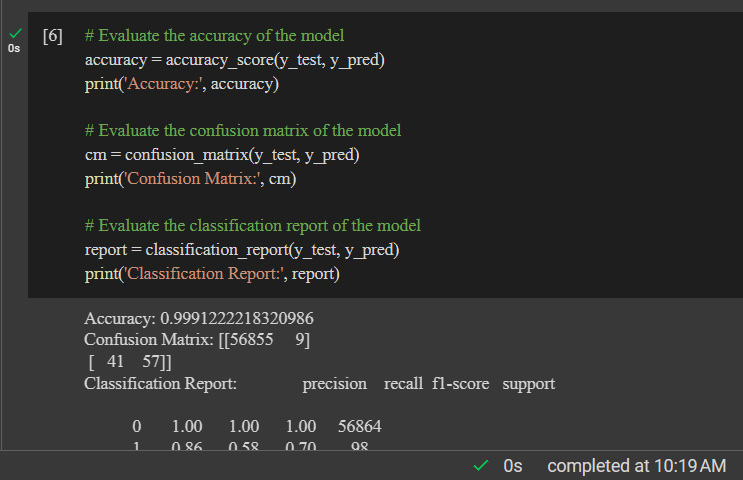
# Evaluate the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
# Evaluate the confusion matrix of the model
cm = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:', cm)
# Evaluate the classification report of the model
report = classification_report(y_test, y_pred)
print('Classification Report:', report)
Final Output and Results
Conclusion:
In this article we have gone through process of building machine learning model to detect credit card fraud using Python and a publicly available dataset. We have used Google Colab as running environment and the logistic regression algorithm to predict the target variable. We have evaluated performance of the model using accuracy, confusion matrix, and classification report.