Speech Emotion Recognition using MLP
In this article we will provide the implementation of Speech Emotion Recognition using MLP. Urdu language is used as a primary language to detect emotions from speech.
Hello, My name is Muhammad Umar. I’m a Lecturer of Computer Science. Email me if you need any other help: mohammadumar146@gmail.com. Please share the article to appreciate my work.
We have used 4 basic emotions sad, happy, angry, and neutral. Emotions are assigned labels as 01, 02, 03, 04 as we will see in the code section.
Video on Speech Emotion Recognition using MLP
Speech Emotion Recognition using CNN
IDE used for Speech Emotion Recognition using MLP
We used Google Colab as the development environment.
Place your dataset into your Google Drive
You can also read:
URL Shortener App in Python with Output
Python Program to Download Youtube Videos
So let’s dig into code:
Following code is machine learning model that can recognize emotions in sound files. This is an important application of artificial intelligence that can be used in a variety of fields including speech recognition, music analysis, and mental health diagnosis.
Here is a step-by-step description of the code:
In this article, we will go through the steps required to train a machine learning model to recognize emotions in audio files using the Urdu dataset. We will be using the Python library Librosa to extract features such as MFCC, chroma, and mel from the audio files. We will then use the MLPClassifier from Scikit-learn to train our model.
Step 1: Import the required libraries First, we need to import the required libraries. In this case, we will be using Librosa, Soundfile, os, glob, pickle, numpy, Scikit-learn, and MLPClassifier.
Install Libraries
!pip install librosa soundfile numpy sklearn pyaudioImport Libraries
import librosa
import soundfile
import os, glob, pickle
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_scoreFeatures Extraction
Extract features from audio files Next, we will define a function that will extract features such as MFCC, chroma, and mel from a given audio file. The function takes in the file name, a boolean for MFCC, chroma, and mel, respectively. It returns an array of the extracted features.
# - Extract features (mfcc, chroma, mel) from a sound file
def extract_feature(file_name, mfcc, chroma, mel):
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
#X = sound_file.read()
sample_rate=sound_file.samplerate
X, sample_rate = librosa.load(file_name)
#sample_rate=sound_file.samplerate
if chroma:
stft=np.abs(librosa.stft(X))
result=np.array([])
if mfcc:
mfccs=np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result=np.hstack((result, mfccs))
if chroma:
chroma1=np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)
result=np.hstack((result, chroma1))
if mel:
mel1=np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0)
result=np.hstack((result, mel1))
return resultLabeling Emotions From Dataset
#Emotions in the dataset
emotions={
'03':'03',
'02':'02',
'04':'04',
'01':'01',
}
# - Emotions to observe
observed_emotions=['01', '02', '03', '04']Dataset Loading from Google Drive
# - Load the data and extract features for each sound file
def load_data(test_size=0.2):
x,y=[],[]
for file in glob.glob("./drive/My Drive/data/Emotion_*/*.wav"):
file_name=os.path.basename(file)
emotion=emotions[file_name.split("-")[1]]
if emotion not in observed_emotions:
continue
feature=extract_feature(file, mfcc=True, chroma=True, mel=True)
x.append(feature)
y.append(emotion)
feature = [int(x) for x in feature]
return train_test_split(np.asarray(x), np.asarray(y), test_size=test_size, random_state=15)Dividing Dataset For Training and Testing
x_train, x_test, y_train, y_test = load_data(test_size=0.25)
Build MLP Model
model=MLPClassifier(alpha=0.01, batch_size=256, epsilon=1e-08, hidden_layer_sizes=(300,), learning_rate='adaptive', max_iter=500)
model.fit(x_train,y_train)
y_pred=model.predict(x_test)Calculating Accuracy
# - Calculate the accuracy of our model
accuracy=accuracy_score(y_true=y_test, y_pred=y_pred)
# - Print the accuracy
print("Accuracy: {:.2f}%".format(accuracy*100))Calculating Precision, Recall, F1 Score
from sklearn.metrics import classification_report
print(classification_report(y_test,y_pred))
If you need any help, Please comment I’m happy to help.
Explaining Dataset
Your dataset should be in the following manner:
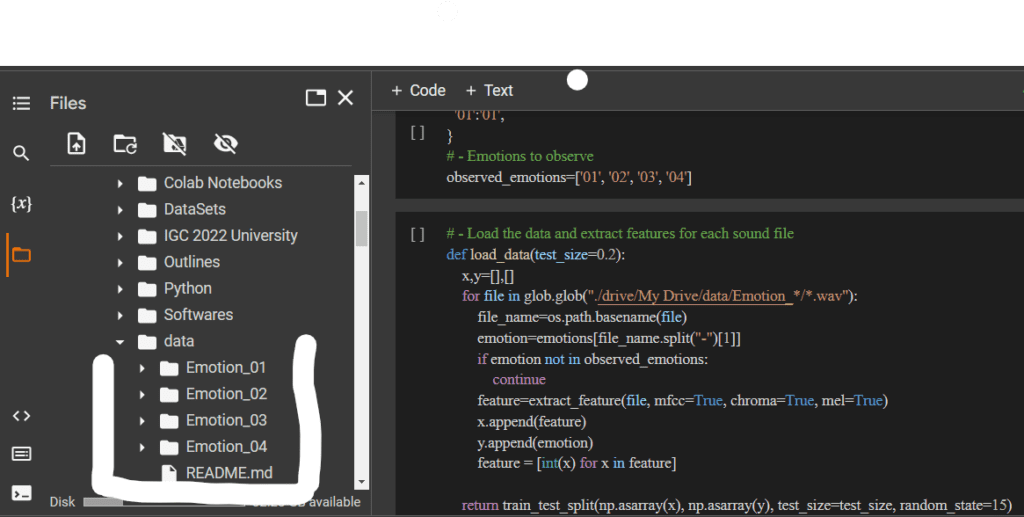
Create Four Folders for 4 Emotions Sad, Happy, Netural, and Angry Like:
Sad: Emotion_01
Happy: Emotion_02
as shown in the picture below
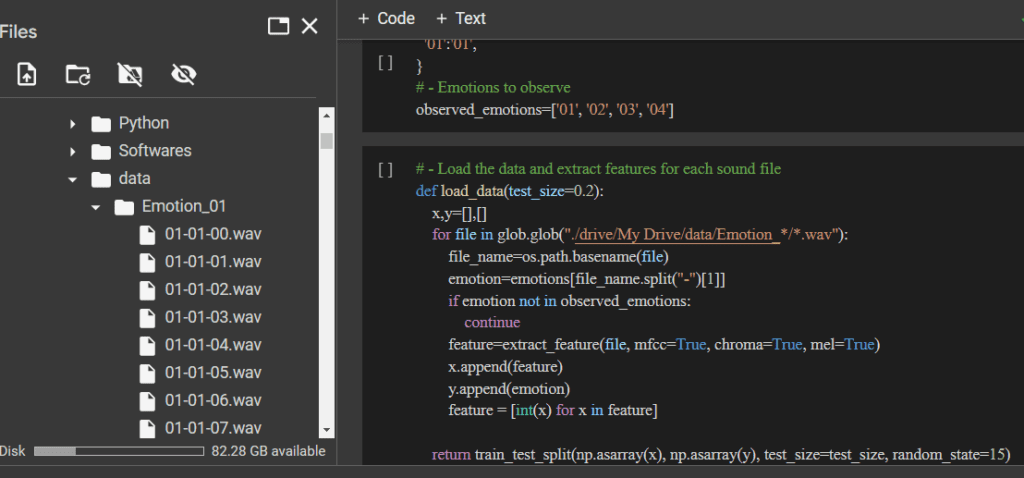
Then in Emotion_01 Folder Lable emotion audio file as 01-01-00 for first emotion and so on. For Emotion_02 Folder name emotion file as 02-02-00 and so on.As shown in below picture.
Download Dataset
Here are some useful links related to the code provided:
- librosa documentation: https://librosa.org/doc/latest/index.html
- soundfile documentation: https://pysoundfile.readthedocs.io/en/latest/
- numpy documentation: https://numpy.org/doc/stable/
- scikit-learn documentation: https://scikit-learn.org/stable/
- pyaudio documentation: https://people.csail.mit.edu/hubert/pyaudio/docs/
- How to install Python packages using pip: https://realpython.com/what-is-pip/
- How to use glob to find files in Python: https://www.geeksforgeeks.org/how-to-use-glob-to-find-files-recursively-in-python/
- One-hot encoding in scikit-learn: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
- Label encoding in scikit-learn: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
- Keras documentation: https://keras.io/api/
- Convolutional Neural Networks (CNNs) in Keras: https://keras.io/guides/sequential_model/
- RMSprop optimizer in Keras: https://keras.io/api/optimizers/rmsprop/