Write a Python Program to Detect Abusive Comment
In today’s world social media platforms are commonly used to share ideas and opinions. However with increase in usage problem of abusive comments has also increased. These comments can hurt people’s feelings and can lead to serious mental health issues. Therefore it is essential to develop programs that can detect such comments and prevent them from spreading. In this article we will learn how to write a Python Program to Detect Abusive Comment or Not.
Step 1: Import necessary libraries
In the first step we need to import necessary libraries. We will be using pandas library to load and manipulate dataset re library to preprocess text CountVectorizer from sklearn to extract features using Bag of Words train_test_split from sklearn to split dataset into training and testing sets SVC from sklearn to train SVM model and classification_report from sklearn.metrics to evaluate performance of the SVM model.
import pandas as pd
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report
Step 2: Load and preprocess dataset
Next we need to load and preprocess dataset. We will using Twitter Sentiment Analysis dataset that contains tweets labeled as either hateful or not hateful.
# Load the dataset
data = pd.read_csv('/kaggle/input/twitter-sentiment-analysis-hatred-speech/train.csv')
# Remove unnecessary columns
data = data.drop(['id'], axis=1)
# Preprocess the text
def preprocess_text(text):
# Remove URLs
text = re.sub(r'http\S+', '', text)
# Remove usernames
text = re.sub(r'@[^\s]+', '', text)
# Remove special characters
text = re.sub(r'[^\w\s]', '', text)
return text
data['tweet'] = data['tweet'].apply(preprocess_text)
Here we are loading dataset from the path ‘/kaggle/input/twitter-sentiment-analysis-hatred-speech/train.csv’ and dropping unnecessary column ‘id’. Then we are defining function preprocess_text to remove URLs usernames and special characters from tweets. Finally we are applying the preprocess_text function to the ‘tweet’ column of dataset.
Step 3: Extract features using Bag of Words (BoW)
In this step we will using CountVectorizer from sklearn extract features from preprocessed tweets using the Bag of Word approach.
# Extract features using Bag of Words (BoW)
vectorizer = CountVectorizer(stop_words='english')
X = vectorizer.fit_transform(data['tweet'])
# Extract labels
y = data['label']
Here we are initializing a CountVectorizer object with stop_words=’english’ to remove common English stop words. Then we are using fit_transform method of CountVectorizer object extract features from preprocessed tweets and store them in a variable X. We are also extracting labels from the ‘label’ column of dataset and storing them in a variable y.
Step 4: Split the dataset into training and testing sets
In this step we will be splitting dataset into training and testing sets using train_test_split from sklearn.
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Here we are using train_test_split method to split features X and labels y into training and testing sets. We are setting test_size parameter to 0.2 to keep 20% of data for testing and random_state parameter to 42 to ensure that same split is obtained every time the code is run.
Step 5: Train the SVM model
In this step we will using SVC from sklearn to train an SVM model.
# Train the SVM model
svm = SVC(kernel='linear')
svm.fit(X_train, y_train)
Here we initializing SVM model with kernel=’linear’ use linear kernel. Then we using fit method of SVM model to train model on training set (X_train and y_train).
Step 6: Evaluate performance of SVM model
In this step we will be evaluating performance of SVM model on testing set.
# Make predictions on the testing set
y_pred = svm.predict(X_test)
# Evaluate the performance of the SVM model
print(classification_report(y_test, y_pred))
Here we are using predict method of SVM model to make predictions on testing set (X_test). Then we are using classification_report function from sklearn.metrics to evaluate performance of SVM model by printing precision, recall, and F1-score for each label (0 and 1) and overall accuracy.
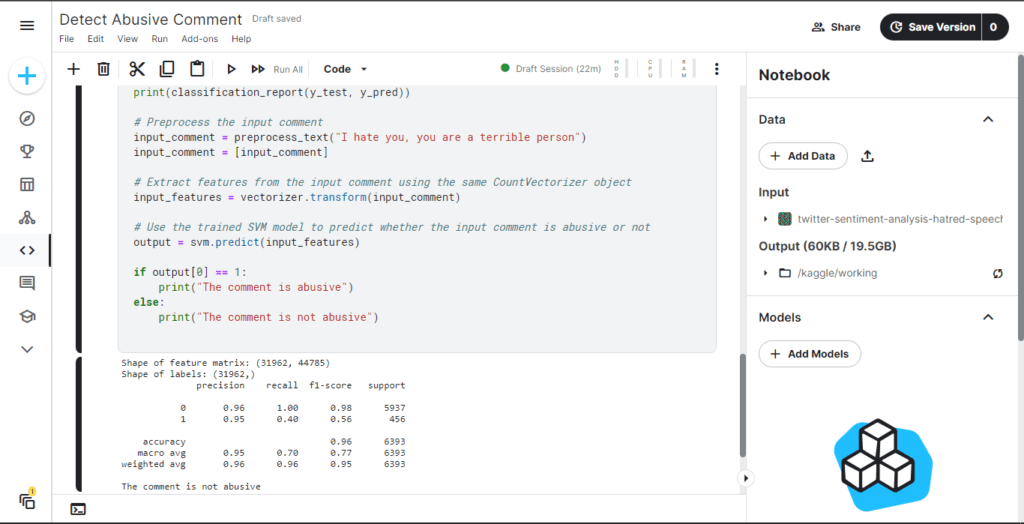
Code Implementation
Here’s the complete code for the program in Python:
import pandas as pd
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# Load the dataset
data = pd.read_csv('/kaggle/input/twitter-sentiment-analysis-hatred-speech/train.csv')
# Remove unnecessary columns
data = data.drop(['id'], axis=1)
# Preprocess the text
def preprocess_text(text):
# Remove URLs
text = re.sub(r'http\S+', '', text)
# Remove usernames
text = re.sub(r'@[^\s]+', '', text)
# Remove special characters
text = re.sub(r'[^\w\s]', '', text)
return text
data['tweet'] = data['tweet'].apply(preprocess_text)
# Extract features using Bag of Words (BoW)
vectorizer = CountVectorizer(stop_words='english')
X = vectorizer.fit_transform(data['tweet'])
# Extract labels
y = data['label']
# Print the shape of the feature matrix and the labels
print('Shape of feature matrix:', X.shape)
print('Shape of labels:', y.shape)
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the SVM model
svm = SVC()
svm.fit(X_train, y_train)
# Evaluate the SVM model on the test set
y_pred = svm.predict(X_test)
print(classification_report(y_test, y_pred))
# Preprocess the input comment
input_comment = preprocess_text("I hate you, you are a terrible person")
input_comment = [input_comment]
# Extract features from the input comment using the same CountVectorizer object
input_features = vectorizer.transform(input_comment)
# Use the trained SVM model to predict whether the input comment is abusive or not
output = svm.predict(input_features)
if output[0] == 1:
print("The comment is abusive")
else:
print("The comment is not abusive")
This code should load the dataset preprocess the text extract features using CountVectorizer split dataset into training and testing sets train SVM model evaluate SVM model on test set and use trained model to predict whether input comment is abusive or not. Please let me know if you have any further questions.
Here are some useful links that can help you learn more about building an abusive language detection model in Python:
- “Abusive Language Detection with Python” tutorial on Towards Data Science: https://towardsdatascience.com/abusive-language-detection-with-python-9350c58a7dac
- “Toxic Comment Classification Challenge” Kaggle competition page: https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge
- “How to Build a Strong Abusive Language Classifier with Python” tutorial on DataCamp: https://www.datacamp.com/community/tutorials/abusive-language-classifier-python
- “Detecting Hate Speech with Machine Learning” tutorial on Real Python: https://realpython.com/python-nltk-sentiment-analysis/
- “Building a Toxic Comment Classifier with Convolutional Neural Networks” tutorial on Medium: https://towardsdatascience.com/building-a-toxic-comment-classifier-with-cnn-and-lstm-in-keras-b0e0a98c3e6d
I hope you find these resources helpful!