Speech Emotion Recognition using CNN
In this article we will provide the implementation of Speech Emotion Recognition using CNN. Urdu language is used as a primary language to detect emotions from speech.
Hello, My name is Muhammad Umar. I’m a Lecturer of Computer Science. Email me if you need any other help: mohammadumar146@gmail.com. Please share the article to appreciate my work.
We have used 4 basic emotions sad, happy, angry, and neutral. Emotions are assigned labels as 01, 02, 03, 04 as we will see in the code section.
Speech Emotion Recognition using MLP
IDE used for Speech Emotion Recognition using CNN
We used Google Colab as the development environment.
Place your dataset into your Google Drive
You can also read:
URL Shortener App in Python with Output
Python Program to Download Youtube Videos
So let’s dig into code:
Following code is machine learning model that can recognize emotions in sound files. This is an important application of artificial intelligence that can be used in a variety of fields including speech recognition, music analysis, and mental health diagnosis.
Here is a step-by-step description of the code:
- The first line
!pip install librosa soundfile numpy sklearn pyaudioinstalls the required libraries using pip. - The
importstatements bring in the necessary libraries and modules. - The
extract_featurefunction takes a file name as input, reads the sound file, and extracts various features like MFCC, chroma, and mel from it. - A dictionary named
emotionsis defined which maps the emotion codes to their respective emotions. - A list named
observed_emotionsis defined that includes the emotions to be observed. - The
load_datafunction loads the data from the sound files, extracts the features, and prepares the data for training the model. It loops through all the files in the directory “./drive/My Drive/data/Emotion_/.wav” and extracts the emotion code from the filename. If the emotion is not in theobserved_emotionslist, the loop continues to the next file. Otherwise, the features are extracted using theextract_featurefunction, and both the features and the emotion code are appended to thexandylists respectively. - The
load_datafunction then splits the data into training and testing sets using thetrain_test_splitfunction from thesklearn.model_selectionmodule. - The training and testing sets are converted to NumPy arrays and then to one-hot encoded arrays using the
LabelEncoderandnp_utils.to_categoricalfunctions from thesklearn.preprocessingandkeras.utilsmodules, respectively. - The training and testing sets are then reshaped using the
np.expand_dimsfunction so that they can be used as input to the convolutional neural network. - A
Sequentialmodel is created using theConv1D,MaxPooling1D,Flatten,Dropout,Dense, andActivationlayers from thekeras.layersmodule. - The
modelis compiled with aRMSpropoptimizer,categorical_crossentropyloss function, andaccuracymetric. - The model is then trained on the training data using the
fitmethod with a batch size of 16 and 500 epochs. - Finally, the model is evaluated on the testing data using the
evaluatemethod, and the accuracy of the model is printed.
Install Libraries
!pip install librosa soundfile numpy sklearn pyaudioImport Libraries
import librosa
import soundfile
import os, glob, pickle
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreFeature Extraction Function
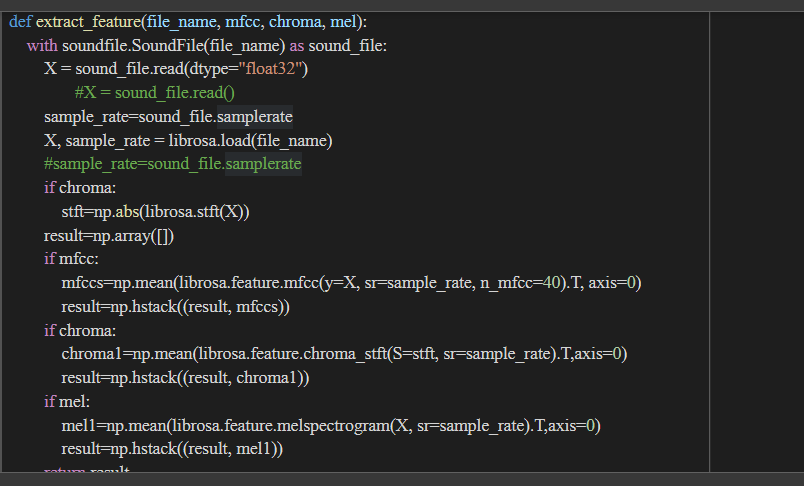
#Extract features (mfcc, chroma, mel) from a sound file
def extract_feature(file_name, mfcc, chroma, mel):
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
#X = sound_file.read()
sample_rate=sound_file.samplerate
X, sample_rate = librosa.load(file_name)
#sample_rate=sound_file.samplerate
if chroma:
stft=np.abs(librosa.stft(X))
result=np.array([])
if mfcc:
mfccs=np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result=np.hstack((result, mfccs))
if chroma:
chroma1=np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)
result=np.hstack((result, chroma1))
if mel:
mel1=np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0)
result=np.hstack((result, mel1))
return resultLabeling Emotions From Dataset
#Emotions in the dataset
emotions={
'03':'03',
'02':'02',
'04':'04',
'01':'01',
}
# - Emotions to observe
observed_emotions=['01', '02', '03', '04']Dataset Loading from Google Drive
# - Load the data and extract features for each sound file
def load_data(test_size=0.2):
x,y=[],[]
for file in glob.glob("./drive/My Drive/data/Emotion_*/*.wav"):
file_name=os.path.basename(file)
emotion=emotions[file_name.split("-")[1]]
if emotion not in observed_emotions:
continue
feature=extract_feature(file, mfcc=True, chroma=True, mel=True)
x.append(feature)
y.append(emotion)
feature = [int(x) for x in feature]
return train_test_split(np.asarray(x), np.asarray(y), test_size=test_size, random_state=15)Dividing Dataset For Training and Testing
x_train, x_test, y_train, y_test = load_data(test_size=0.25)
X_train = np.array(x_train)
y_train = np.array(y_train).ravel()
X_test = np.array(x_test)
y_test = np.array(y_test).ravel()One Hot Encoding
# One-Hot Encoding
from sklearn.preprocessing import LabelEncoder
from keras.utils import np_utils
lb = LabelEncoder()
y_train = np_utils.to_categorical(lb.fit_transform(y_train))
y_test = np_utils.to_categorical(lb.fit_transform(y_test))
x_traincnn =np.expand_dims(X_train, axis=2)
x_testcnn= np.expand_dims(X_test, axis=2)Build CNN Model
# To build Neural Network and Create desired Model
import keras
from keras.models import Model
from keras.models import Sequential
from keras.layers import Conv1D, MaxPooling1D #, AveragePooling1D
from keras.layers import Flatten, Dropout, Activation # Input,
from keras.layers import Dense #, Embeddi
model = Sequential()
model.add(Conv1D(256, 5,padding='same',input_shape=(x_traincnn.shape[1],x_traincnn.shape[2])))
model.add(Activation('relu'))
model.add(Conv1D(128, 5,padding='same'))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(MaxPooling1D(pool_size=(8)))
model.add(Conv1D(128, 5,padding='same',))
model.add(Activation('relu'))
model.add(Conv1D(128, 5,padding='same',))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(y_train.shape[1]))
model.add(Activation('softmax'))
opt = keras.optimizers.RMSprop(lr=0.00001, decay=1e-6)
model.summary()
model.compile(loss='categorical_crossentropy', optimizer=opt,metrics=['accuracy'])Fitting Model
cnnhistory=model.fit(x_traincnn, y_train, batch_size=16, epochs=500, validation_data=(x_testcnn, y_test))Saving Model
model_name = 'umar.h5'
save_dir = os.path.join(os.getcwd(), 'Trained_Models')
# Save model and weights
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
model_path = os.path.join(save_dir, model_name)
model.save(model_path)
print('Saved trained model at %s ' % model_path)
import json
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)Loading JSON and creating model
# loading json and creating model
from keras.models import model_from_json
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# load weights into new model
loaded_model.load_weights("./Trained_Models/umar.h5")
print("Loaded model from disk")
# evaluate loaded model on test data
loaded_model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
score = loaded_model.evaluate(x_testcnn, y_test, verbose=0)
print("%s: %.2f%%" % (loaded_model.metrics_names[1], score[1]*100))Accuracy
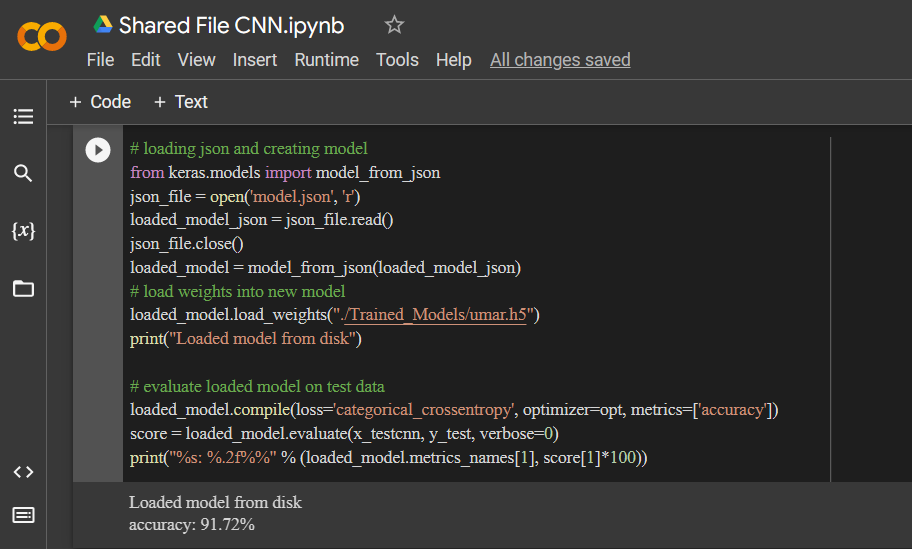
If you need any help, Please comment I’m happy to help.
Explaining Dataset
Your dataset should be in the following manner:
Create Four Folders for 4 Emotions Sad, Happy, Netural, and Angry Like:
Sad: Emotion_01
Happy: Emotion_02
as shown in the picture below
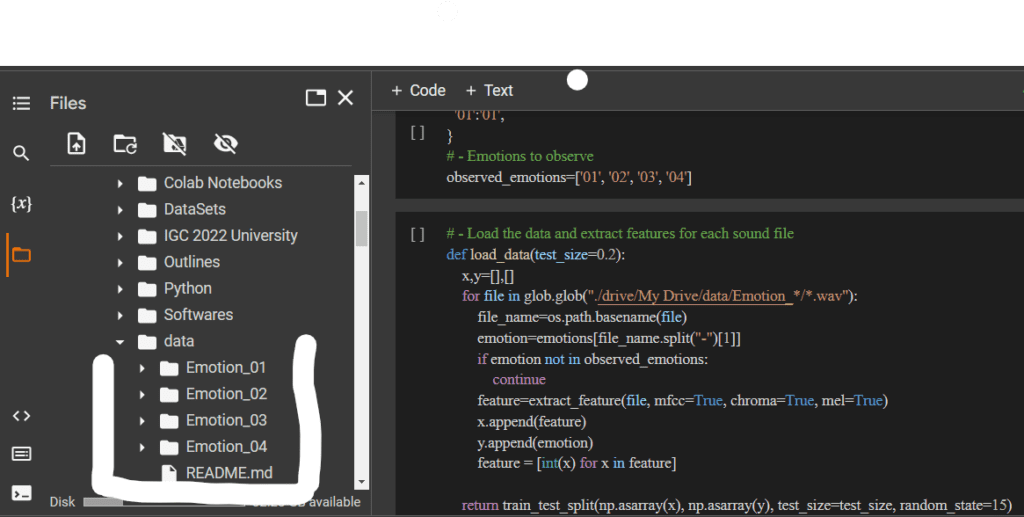
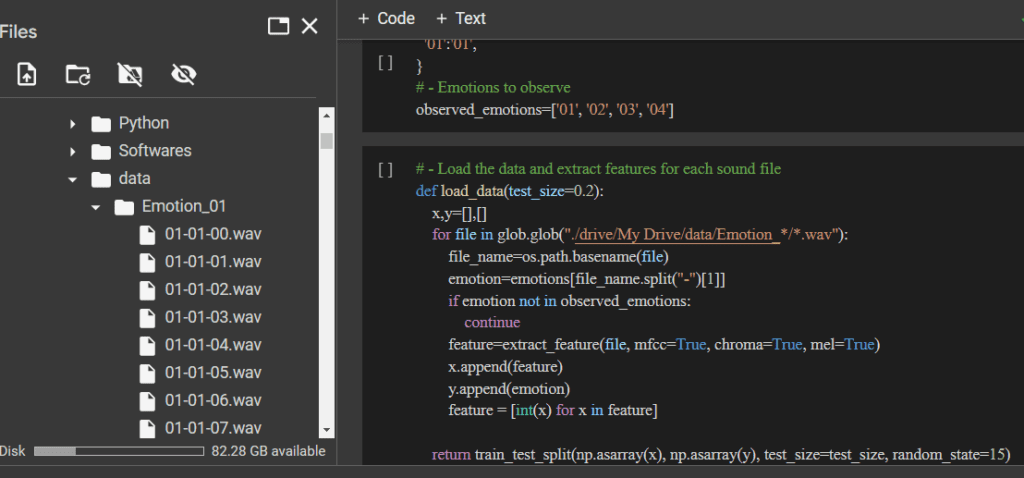
Then in Emotion_01 Folder Lable emotion audio file as 01-01-00 for first emotion and so on. For Emotion_02 Folder name emotion file as 02-02-00 and so on.As shown in below picture.
Download Dataset
Here are some useful links related to the code provided:
- librosa documentation: https://librosa.org/doc/latest/index.html
- soundfile documentation: https://pysoundfile.readthedocs.io/en/latest/
- numpy documentation: https://numpy.org/doc/stable/
- scikit-learn documentation: https://scikit-learn.org/stable/
- pyaudio documentation: https://people.csail.mit.edu/hubert/pyaudio/docs/
- How to install Python packages using pip: https://realpython.com/what-is-pip/
- How to use glob to find files in Python: https://www.geeksforgeeks.org/how-to-use-glob-to-find-files-recursively-in-python/
- One-hot encoding in scikit-learn: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
- Label encoding in scikit-learn: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
- Keras documentation: https://keras.io/api/
- Convolutional Neural Networks (CNNs) in Keras: https://keras.io/guides/sequential_model/
- RMSprop optimizer in Keras: https://keras.io/api/optimizers/rmsprop/