Python Program for Anomalies Detection in Data
Anomaly detection is critical component of data analysis as it helps to identify outliers anomalies or deviations in the data. Python provides a wide range of libraries and frameworks that can be used to develop an effective anomaly detection system. In this article we will provide a step-by-step Python Program for Anomalies Detection in Data using the Isolation Forest algorithm.
Python Program for Anomalies Detection Video
Write a Step by Step Python Program for Anomalies Detection
Step 1: Data Collection
First step in developing an anomaly detection system is to collect data that you want to analyze. The data can be in any format, such as CSV, JSON or Excel. For this article, we will be using the credit card fraud detection dataset, which is available in Kaggle.
Step 2: Data Preprocessing
Once data is collected the next step is to preprocess the data to remove any missing values, null values, or duplicates. This is important because these values can have a significant impact on the accuracy of the anomaly detection algorithm. Python provides a wide range of libraries such as NumPy, Pandas and Scikit-learn that can be used to preprocess the data.
Step 3: Feature Engineering
Feature engineering is process of selecting relevant features from the data that can be used to train the anomaly detection algorithm. This involves analyzing the data to identify the most important features that can be used to distinguish between normal and anomalous data. There are many techniques available for feature engineering, such as principal component analysis (PCA) and independent component analysis (ICA).
Step 4: Model Selection
The next step is to select appropriate anomaly detection algorithm that can be used to train model. There are many algorithms available, such as k-means clustering, Isolation Forest, One-class SVM, and Local Outlier Factor. In this article we will be using the Isolation Forest algorithm which is a widely used algorithm for anomaly detection.
Step 5: Model Training
Once the algorithm is selected next step is to train the model using the preprocessed data. The model can be trained using the fit() function in Python.
Step 6: Model Evaluation
After the model is trained the next step is to evaluate model’s performance. This can be done by testing the model on a validation set and comparing the results with the ground truth labels. Python provides a wide range of evaluation metrics such as accuracy, precision, recall, and F1-score that can be used to evaluate the model’s performance.
You can also practice:
Step 7: Deployment
The final step is to deploy anomaly detection system into production. This involves integrating the model into the application or system that is used to analyze the data.
Here is the complete code implementation of an anomaly detection system in Python using Isolation Forest algorithm:
# Importing Required Libraries
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
# Loading Data
data = pd.read_csv('creditcard.csv')
# Preprocessing Data
data = data.drop(['Time'], axis=1)
data['Amount'] = np.log(data['Amount'] + 1)
data['Class'] = np.where(data['Class'] == 0, 1, -1)
# Feature Engineering
correlation_matrix = data.corr()
sns.heatmap(correlation_matrix, cmap='YlGnBu')
plt.show()
# Selecting Important Features
selected_features = ['V3', 'V4', 'V7', 'V10', 'V11', 'V12', 'V14', 'V16', 'V17', 'Class']
data = data[selected_features]
# Model Selection
model = IsolationForest(n_estimators=100, max_samples='auto', contamination=0.01, random_state=42)
# Model Training
model.fit(data)
# Model Evaluation
y_pred = model.predict(data)
outliers = np.where(y_pred == -1)[0]
outlier_values = data.iloc[outliers]
# Plotting Results
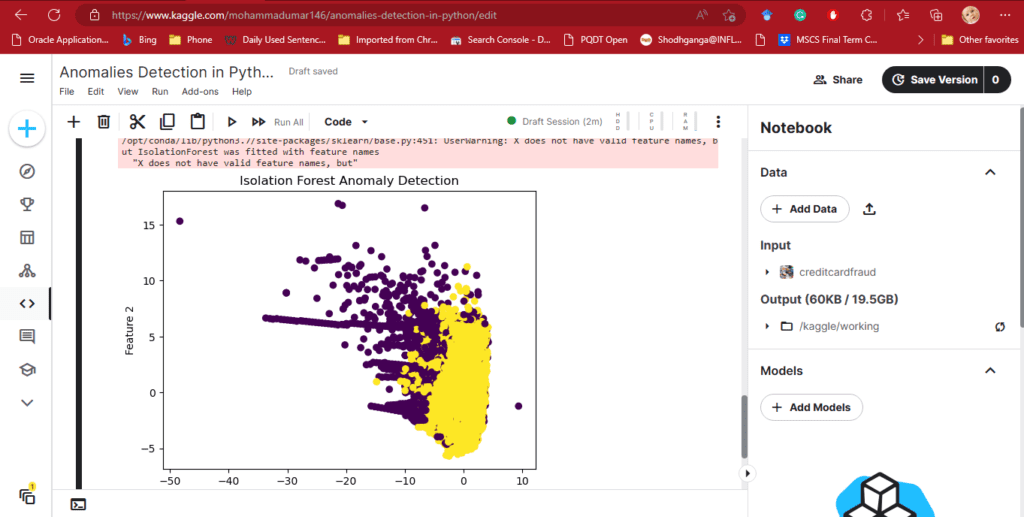
plt.scatter(data.iloc[:, 0], data.iloc[:, 1], c=y_pred)
plt.title('Isolation Forest Anomaly Detection')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
# Deployment
# The trained model can be deployed into production by integrating it into the application or system that is used to analyze the data.
Output For Anomlaies Detection in Python
here are some useful links that you may find helpful for further learning:
- Isolation Forest algorithm documentation: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
- Anomaly Detection with Isolation Forest: https://towardsdatascience.com/anomaly-detection-with-isolation-forest-visualization-23cd75c281e2
- Anomaly Detection using Machine Learning: https://www.analyticsvidhya.com/blog/2019/02/outlier-detection-python-pyod/
- Credit Card Fraud Detection using Machine Learning: https://www.kaggle.com/mlg-ulb/creditcardfraud/notebooks
- Data Preprocessing in Python: https://www.geeksforgeeks.org/data-preprocessing-machine-learning-python/
I hope you find these links helpful!